
M5StackのModule-LLMで使用できるLLMモデルを使って、日本語による問題の正解率と解答にかかった時間を測定してみました。日本語を理解する能力、文脈を理解して計算する能力、知識の豊富さを示す能力がどれくらいあるのかを試していきます。
【はじめに】
この記事は結果を貼り付けただけで、特に結果の考察はしていません。それは、考察できるほどLLMの知識が無いからです!!(おっと開き直ったぞw)得意の知ったかぶりも今回はやめておきます。
Module-LLMで使用されているNPU AX630Cは3.2 TOPS (int8)の性能があり、CPUでの演算能力よりもはるかに強力です。RTX 4090は1321 TOPS 、H100は3026 TOPS(※ChatGPT調べ)とは桁違いですが、こんな小さくて低消費電力なデバイスで、どこまで高火力なマシンと戦えるのか見ていきたいと思います。
システム構成
今回のベンチマークでは前回作成したプログラムの流用して、APIを経由して実行しています。gradioを使うとAPIを扱うのがとても楽です。
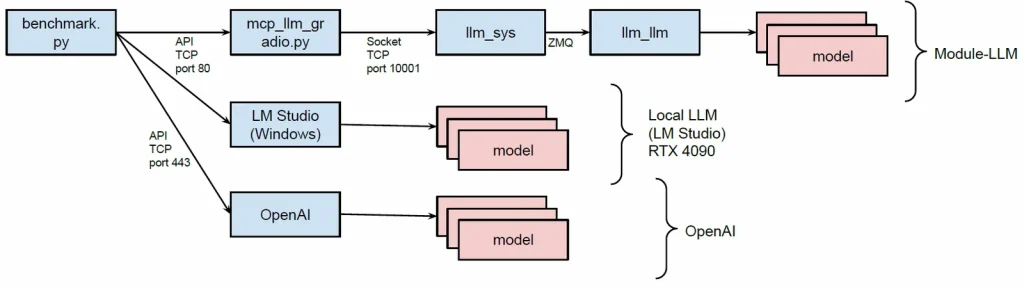
Module-LLMだけでなく、ローカルで動いているLM Studioのモデルと、OpenAIのモデルも同じプログラムでベンチマークできます。
テスト内容
ベンチマークのテスト問題には、日本語Chain-of-Thoughtデータセット t-nakabayashi/chain-of-thought-ja-benchmark とJAQKET: クイズを題材にした日本語QAデータセット のデータを使用させていただきました。回答は全て数値で、正誤の判定は数値が一致するかどうかで判断しました。
テスト: jcommonsenseqa
(test.json) jcommonsenseqa は常識的な文脈理解を測ります。たとえば「どちらがよりあり得るか」「○○が壊れた理由は?」など、暗黙の前提や一般常識を踏まえて正答を選びます。以下は実際の問題の例です。
問題:電子機器で使用される最も主要な電子回路基板の事をなんと言う?
(0)掲示板
(1)パソコン
(2)マザーボード
(3)ハードディスク
(4)まな板
正解:(2)マザーボードテスト: mapws
(test.json) mapws は基本的な計算の能力を測ります。ただし単純な計算式ではなく、文脈を理解しながら問題を解く必要があります。計算自体は足し算や引き算など小学生レベルです。以下は実際の問題の例です。
問題:山田は浜辺で70個の貝殻を見つけました。彼女は佐々木に貝殻をいくつかあげました。彼女は今27個の貝殻を持っています。山田は佐々木に何個の貝殻をあげましたか?
正解:43テスト: mgsm
(test.json) mgsm は先ほどのmapwsと似ていますが、より複雑になっており、複数ステップの数理推論力が求められます。以下は実際の問題の例です。
問題:ジャネットのアヒルは1日に16個の卵を生みます。ジャネットは毎朝朝食の一環で3個を消費し、毎日4個使って友達向けにマフィンを焼きます。残りを市場で1個あたり2ドルの価格で売ります。彼女は毎日市場でいくら手に入れていますか?
正解:38テスト: jaqket
(dev1_questions.json) jaqketはWikipediaの記事名を答えとしたクイズ問題です。以下は実際の問題の例です。
問題:明治時代に西洋から伝わった「テーブル・ターニング」に起源を持つ占いの一種で、50音表などを記入した紙を置き、参加者全員の人差し指をコインに置いて行うのは何でしょう?
(0) テケテケ
(1) 毛羽毛現
:
(14) コックリさん
(15) 紫の鏡
:
解答:(14) コックリさんベンチマークに使用したプログラム
プログラムは GitHub にアップしました。
| ファイル | 内容 |
|---|---|
| mcp_llm_gradio.py | Module-LLMをAPI化するためのプログラム。元々はMCPサーバーとして使用するためのものだった。 |
| benchmark.py | ベンチマークを行うプログラム |
| totalling.py | 採点、集計を行うプログラム |
| change_model.py | Module-LLMのモデルを切り替える指示を出すプログラム |
| ファイル | 内容 |
|---|---|
| start_***.sh | ベンチマークの一括実行スクリプト |
| total.sh | 採点、集計を一括実行するスクリプト |
| convert_test_jaqket.py | jaqketのデータセット(json)を他と同じフォーマットのjsonファイルに変換するプログラム |
| plot_graph.py | 集計結果のグラフを作成するプログラム |
| get_modellist_*** | 使用可能なモデルの一覧を取得する |
はじめに start_***.sh でベンチマークを行って結果を集め、最後に total.sh で採点・集計をする流れです。
ベンチマーク結果
結果はあくまでこの自作プログラムでの結果であり、実施方法が異なる他のベンチマーク結果と比較できるものではないことをご留意ください。問題数も100問だけで誤差も大きいです。OpenAIでのベンチマークは課金が怖かったので4o-miniのみ実施です。o4-miniはなぜかAPIがエラーを返してできませんでした。
背景が青の行がModule-LLMの結果です。正解率は正解率/有効な回答数、平均応答時間はその問題を回答し終えるまでに要した時間(ms)、異常は回答結果が異常(ループやタイムアウト)だったの問題数、有効は出題数-異常です。異常な結果が多いモデルは他の結果もあてになりません。
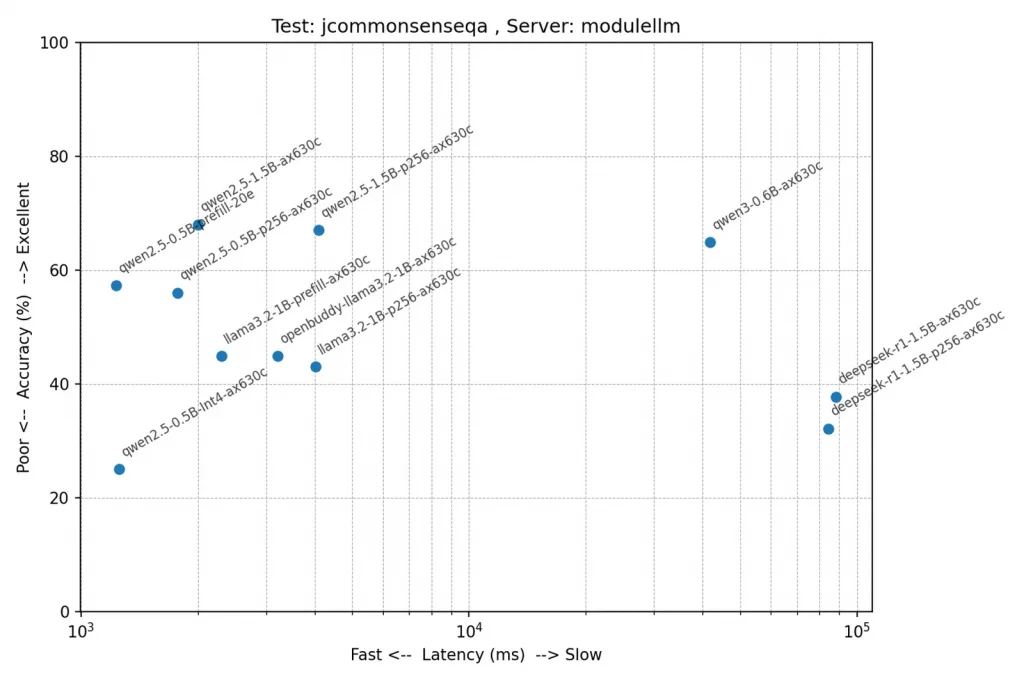
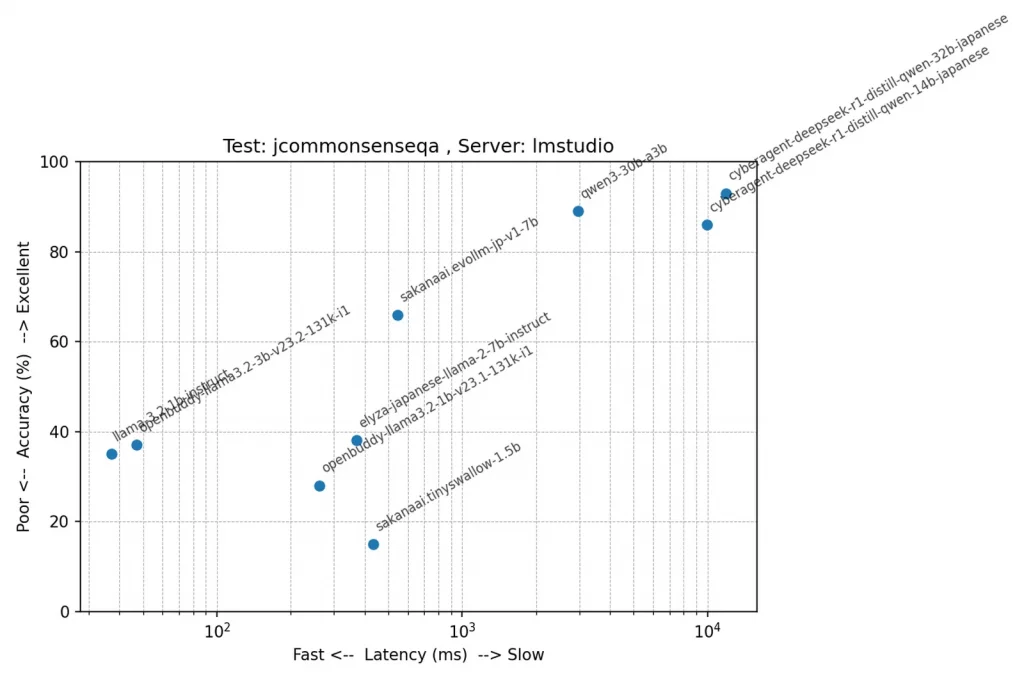
テスト: jcommonsenseqa(常識的な文脈の理解)
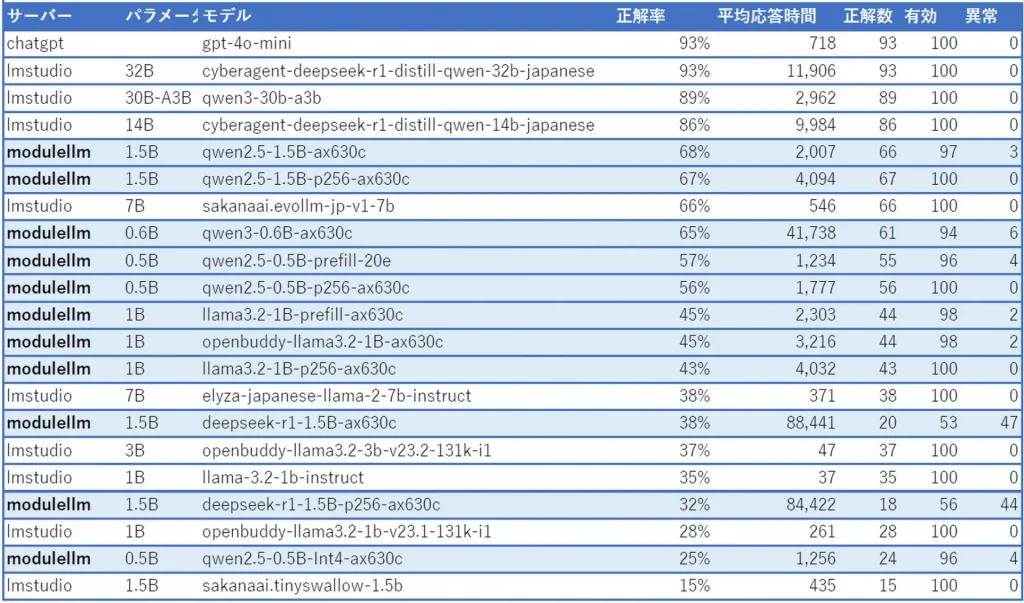
正解率順に並べてみましたが、意外にもqwen2.5の1.5Bモデルが頑張ってますね。テスト問題を見ると文脈の理解というより、出てきた単語と関連性があるかどうかでも答えが出そうですが。このテストは全て5択問題なので、ランダムに答えても平均20%になります。
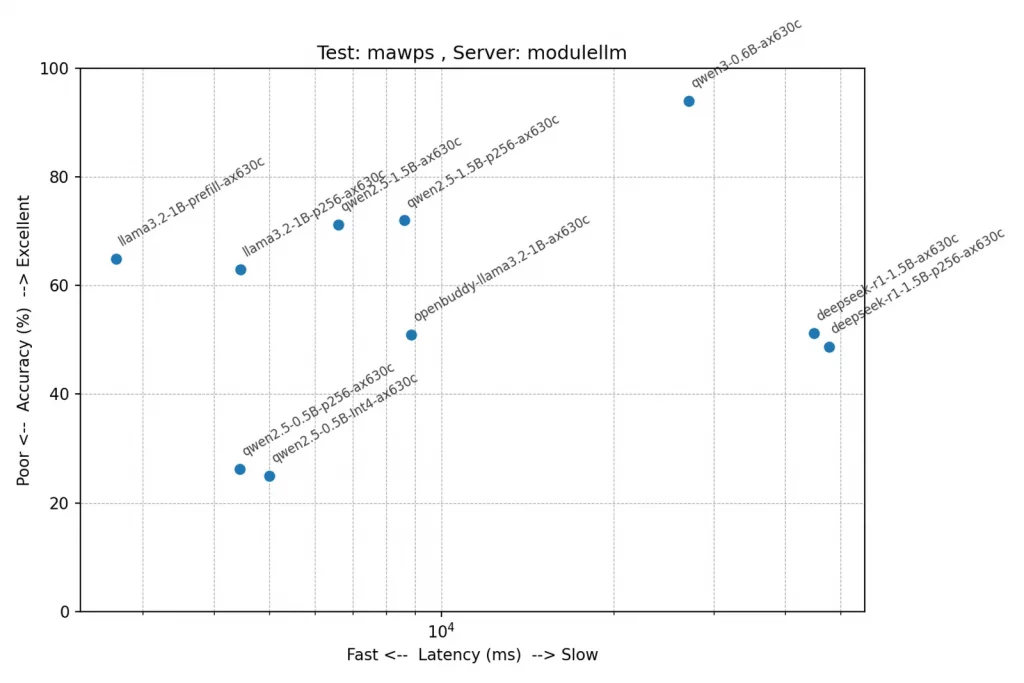
テスト: mawps(文脈を理解し基本的な計算)
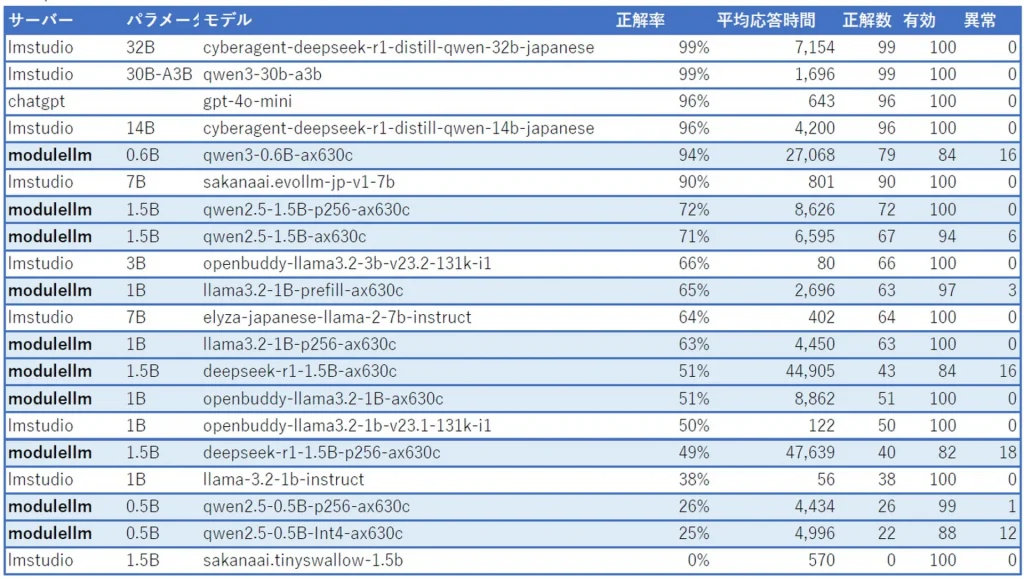
qwen3-0.6B-ax630cの正解率 94% 素晴らしいですね!思考が必要な問題では特に良く発揮できるようです。ただし非常に時間がかかります。応答速度が重視されるチャット用のbotとしては向かないですね。
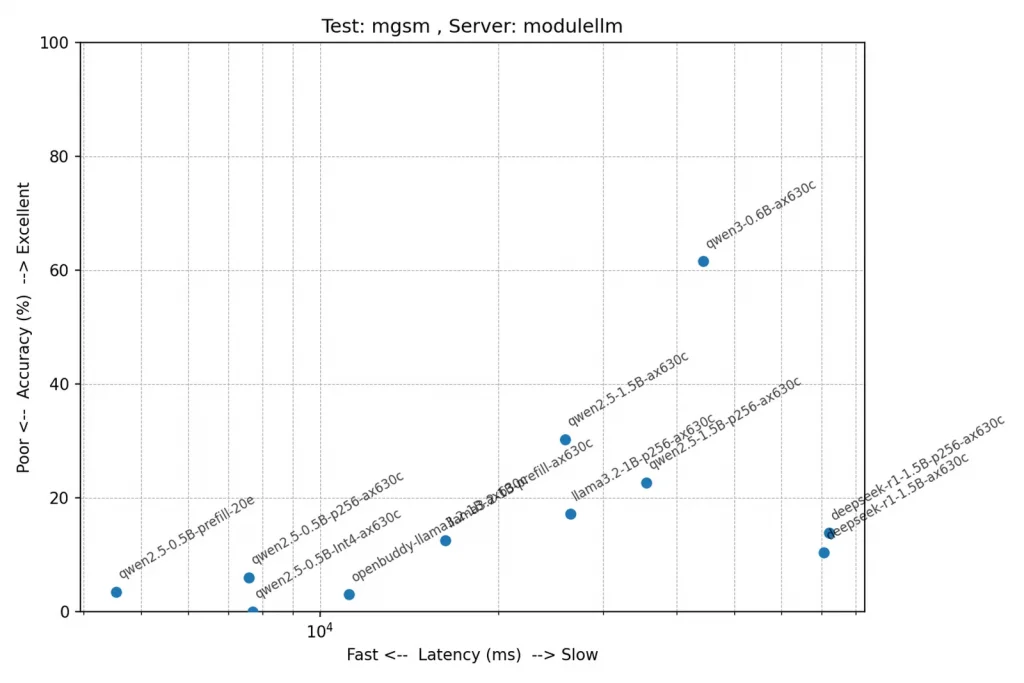
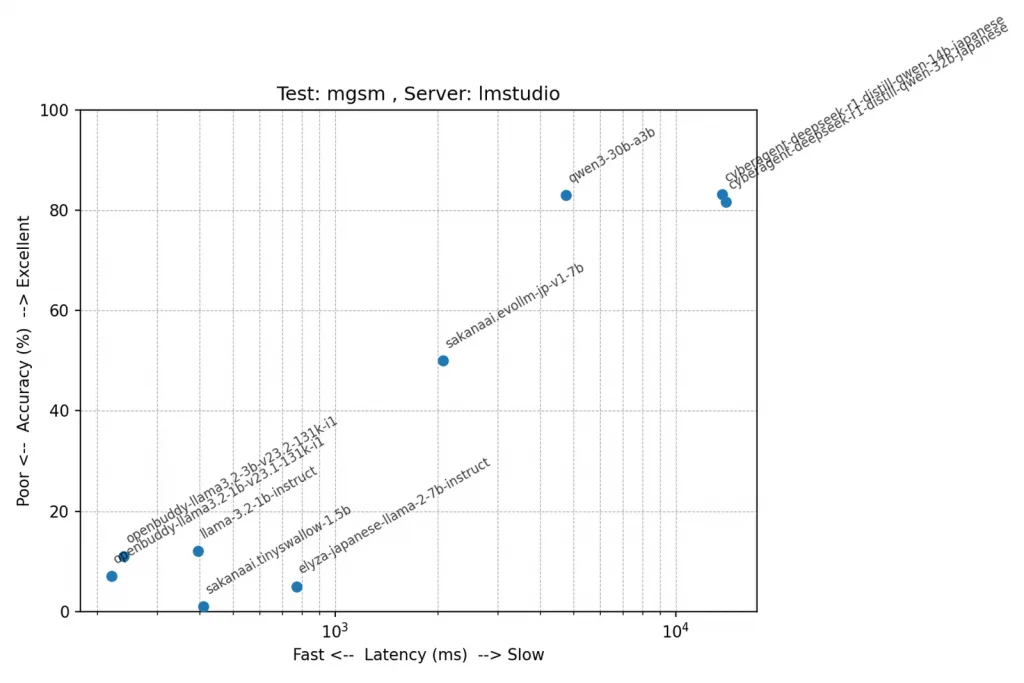
テスト: mgsm(複数ステップの数理推論力)
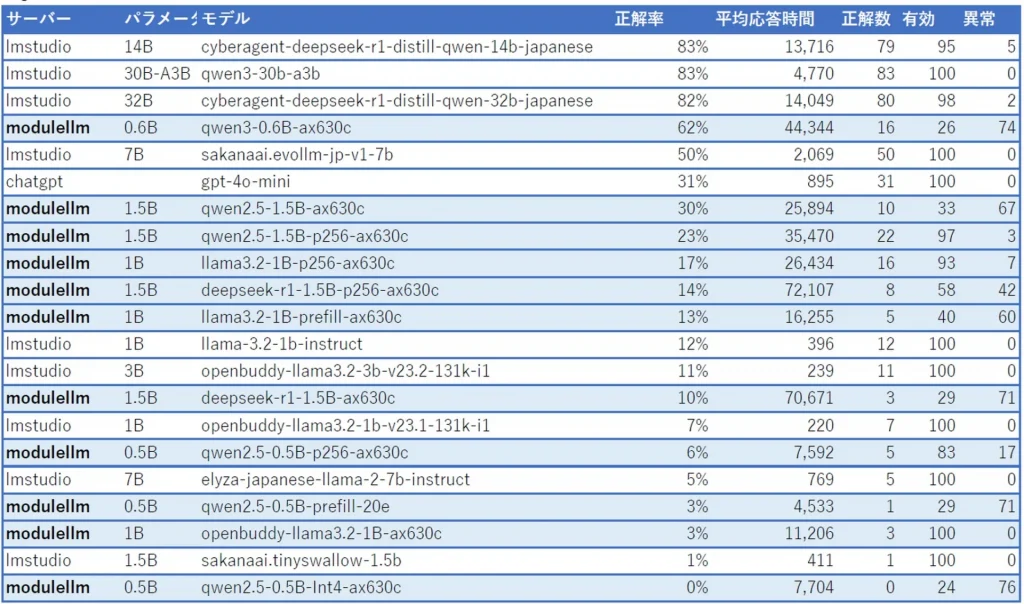
こちらもmawpsと同様にqwen3-0.6B-ax630cが頑張ってますね。正解率上位のモデルと比べると健闘しているのではないでしょうか。そしてgpt-4o-miniを超えちゃってます。これがo4-miniだとまた違うんでしょうけど、o4-miniはエラーでテストできませんでした。
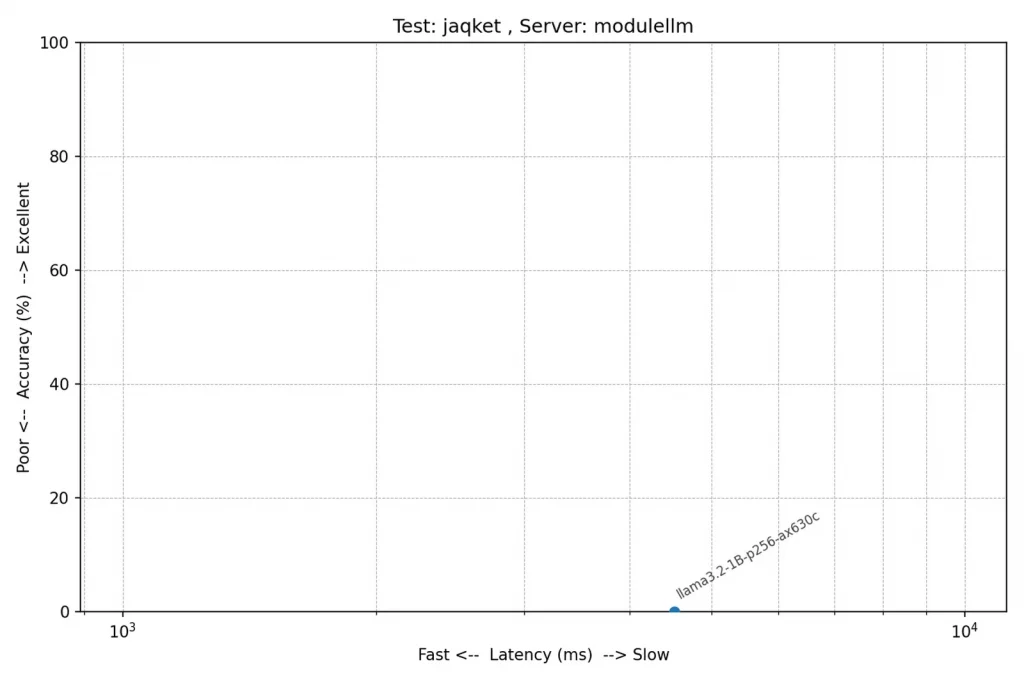
テスト: jaqket(クイズ問題)

jaqketの結果は厳しいものでした。というか、パラメーター数がものを言うテストですね。Module-LLMではほとんどが意味不明なデータのループになってしまいました。このテストは問題が長く選択肢も多いため、入力プロンプトが非常に長くなる傾向があります。詳しく調べていませんが、長すぎるとだめなのかもしれません。
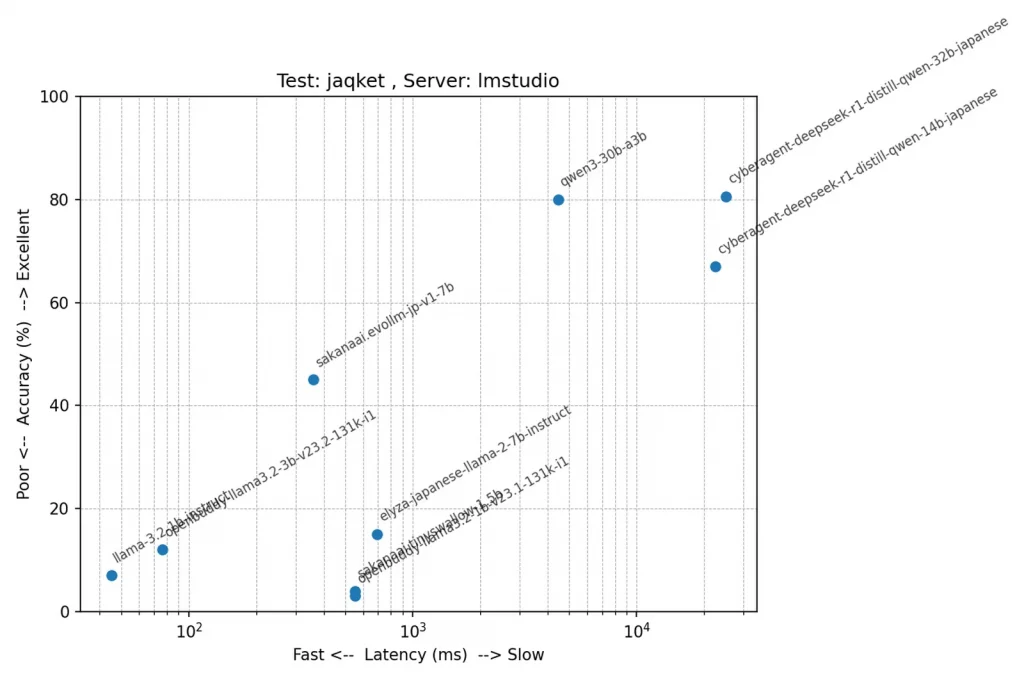
同じような正解率でも、Deepseek R1(32B)とQwen3(30B)とでは全然スピードが違いますね。Qwen3は正確さを保ちながらも高速な推論を実現しています。
その他の話
LLMの回答が自由すぎる
今回行ったベンチマークテストは全ての解答が数字で答えるものです。そのため数字で回答してもらうよう、「数値のみで解答しててください。思考過程や考察は含めないでください。」と指示を与えました。その結果がこれです。
答えは6です
<think>~であるから…</think> [最終解] 4.
The answer is: 3
(1)パソコンです。
##### 7
だいたい$50になります
10+2=12個ですおまえら自由すぎだろ!w
全然指示を守ってくれません。ただルール化できそうだったので、以下のようなルールで解答の数字を抽出するようにしました。
# <think>~</think>タグ内のテキストをすべて削除
response_text = re.sub(r'<think>.*?</think>', '', response_text, flags=re.DOTALL|re.IGNORECASE)
response_text = re.sub(r'^.*</think>', '', response_text, flags=re.DOTALL|re.IGNORECASE)
response_text = re.sub(r'<.*?>', '', response_text, flags=re.DOTALL)
# 「答えはxxです」の場合、xxを抽出
if not answer:
choice_match = re.search(r'答えは\s*([\d\-\.]+)\s*(です)*', response_text)
if choice_match:
answer = choice_match.group(1)
# 「答え: xx」の場合、xxを抽出
if not answer:
choice_match = re.search(r'(答え|解答|正解)は*\s*:*\s*([\d\-\.]+)', response_text)
if choice_match:
answer = choice_match.group(2)
# 「The answer is: xx」の場合、xxを抽出
if not answer:
choice_match = re.search(r'answer is\s*:*\s*([\d\-\.]+)', response_text, re.IGNORECASE)
if choice_match:
answer = choice_match.group(1)
# 選択肢の場合(例: (4)森)、最後の括弧内の数字を抽出
if not answer:
choice_matches = re.findall(r'\((\d+)\)', response_text)
if choice_matches:
answer = choice_matches[-1] # 最後にマッチした括弧内の数字を使用
# 計算式の場合(例: 1+1=2.5=2.5)、最後の等号の後の数字(小数点含む)を抽出
if not answer:
equals_match = re.search(r'=\s*(\d+\.\d+|\d+)(?![^=]*=)', response_text)
if equals_match:
answer = equals_match.group(1)
# 単純に数字だけの場合(例: 4 または 3.14)- 後方一致
if not answer:
number_matches = re.findall(r'(\-?\d+\.\d+|\-?\d+)', response_text)
if number_matches:
answer = number_matches[-1] # 最後にマッチした数値を使用
# 小数点と間違えられた末尾の.や前後の余計なスペースを削除
answer = answer.rstrip('.')
answer = answer.strip()基本的には最後に来る数字が答えの場合が多いのですが、たまに答えの後に解説が続くことがあります。なので明らかに回答である部分があれば先に抽出して、なければ最後の数字のような処理をしています。これ、ほかのベンチマークテストではどうやってるんでしょうかね??
ループの検出
LLMは無限に意味不明な回答を繰り返してしまうことがあります。タイムアウト値を設定しているので設定した時間で止まりますが、意味不明な文字列の中の数字を拾ってしまうと正しく採点ができなくなります。
問題:明治時代に西洋から伝わった...
解答:сь arXiv:1907.04044v1 [math-ph] 10 Jul 2019\narXiv:1907.04044v1 [math-ph] 10 Jul 2019\narXiv:1907.04044v1 [math-ph] 10 Jul 2019\narXiv:1907.04044v1 [math-ph] 10 Jul 2019\narXiv:1907.04よく見るとこの意味不明な文字列も同じ内容の繰り返しです。LLMの出力はストリーミング形式にしているので、これらの文字が細切れでやってきます。この”単語”が出現した回数を数えて、5回以上繰り返した”単語”が3種類以上現れたら無限ループと判断し、強制終了します。
# 同じレスポンスが5回以上続いたものが3種類以上あったら中断(ぐるぐる対策)
if data:
if data in last_responses:
last_responses[data] += 1
# 5回以上続いたレスポンスの種類をカウント(ただし5回につき1種類とカウント)
total_count = 0
over_limit_responses = {}
for k, v in last_responses.items():
if v >= same_response_count:
total_count += v
over_limit_responses[k] = v
if total_count >= same_response_count * same_response_words:
print(f"\n異常検知: {same_response_count}回以上繰り返された応答が{same_response_words}種類に達しました。")
for k, v in over_limit_responses.items():
k_str = k.replace("\n", " ")
print(f" {v}回 : {k_str}")
stop_inference = True
restext = "error"
break
else:
last_responses[data] = 1こんな風に検出されます。
異常検知: 5回以上繰り返された応答が3種類に達しました。
5回 : iv:1
5回 : 907
5回 : .04
LLMの推論を中断します異常検知時やタイムアウト時は推論を終了させます。actionはpauseなので一時停止なんですが、StackFlowには中止するコマンドが無いんですよね。ずっとpauseのままでいいのかわかりませんが、とりあえずこれで止まるのでヨシとします。ヨシ!
def abort_llm():
"""LLMの推論を中止する"""
# https://github.com/m5stack/StackFlow/blob/main/doc/projects_llm_framework_doc/llm_llm_en.md
global llm_work_id
# 中断コマンドを送信(pauseしたままでいいのかは知らない)
try:
request_id = f"pause_{int(time.time())}"
abort_setup = {
"request_id": request_id,
"work_id": llm_work_id,
"action": "pause",
}
send_json_request(sf_sock, abort_setup)
res = receive_response(sf_sock, 20, request_id)
if res and res.get('error', {}).get('code', -999) != 0:
raise Exception(f'推論停止 エラー: {res["error"]["message"]}')
except Exception as e:
print(f'エラー abort_llm: {e}')
return Falseまた、異常時やタイムアウト時はエラーとして扱い、採点を行わないようにしています。このような場合は応答時間が非常に長くなっており、これを平均応答時間に含めると結果が引っ張られてしまうためです。
まとめ
ということでModule-LLMでいろいろと実験をしてみましたが、消費電力1.25W程度で1万円で買える小型デバイスで、ここまで実用的なのはとても興味深いと思いました。OSがUbuntuというのも扱いやすかったですね(自分は元々CentOS使いでしたが)。プログラムは5割がAIによる作成、4割がサジェストを利用してTAB連打w、残り1割が手書きです。AIすごい。