
喋った言葉をずんだもんの口調「~のだ」変えて、ずんだもんの声に変換するマイクを作ってみました。マイクに向かって「今日の天気は晴れです」と喋ると「今日の天気は晴れなのだ」と返ってきます。
今回はさくらインターネットが提供するAIサービス「さくらのAI Engine」を使って実現しました。ちなみに私はさくらの回し者ではありませんよ。回され者です。勝手に回ってるだけです。w
動作デモ
しくみ
大きく分けて、音声認識(文字起こし) → テキスト編集 → 音声合成(テキスト読み上げ)の3つで構成されています。
flowchart LR
1[STT(音声認識)] ---> 2[CHAT(文章作成)] ---> 3[TTS(音声合成)]マイクから入力した声は音声データなので、まずはこれをテキスト(文章化)しなくてはなりません。そこで使うのが音声認識 STT (Speech-to-Text) です。音声データを与えるとその中から言葉を取り出してテキストにしてくれます。
次はこのテキストをずんだもん語(~のだ)に変換します。形態素解析をして単純に「です」→「のだ」に変換するのでもいいいんですが、ここはAIに考えてもらいましょう。CHAT用のAIを使って以下のような指示を与えました。
// システムプロンプト
const String CHAT_SYSTEM_PROMPT =
"ユーザーが入力した文章を、ずんだもんの口調に変更して出力してください。"
"ずんだもんは語尾に「~のだ」「~なのだ」と付ける言葉遣いが特徴です。"
"(例: 天気です→天気なのだ、ありました→あったのだ、行きます→行くのだ、"
"どうしますか?→どうするのだ?、いいですね→いいのだ、わかりません→わからないのだ)"
"ユーザーが入力したテキストを変換した内容だけ出力してください。";AIがずんだもん語に書き換えてくれたら、最後にこれをずんだもんの声にします。音声合成 TTS (Text-to-Speech) のVOICEVOXを使うとテキストからWAV形式の音声データが生成されるので、これをスピーカーで再生します。
使用するハードウェア
今回はM5Stackの ATOMS3R、ATOMIC ECHO BASE、ATOMIC BATTERY BASE を使用しました。

ATOMS3RはATOMS3にPSRAMが搭載された製品で、本体のメモリに加え8MBの外部メモリが使用できます。音声のデータは非常に大きくなるため、512KBのメインメモリ(実際に使用できるのは300KB前後)には収まらない場合があります。外部メモリはSPIで接続されているためメインメモリよりスピードは遅いですが、音声やhttpの受信バッファーに使うぶんには問題ありません。
ATOMIC ECHO BASEはマイクとスピーカーがセットになったユニットです。ATOM S3R ECHOというATOMS3Rにマイクとスピーカーが付いた製品もありますが、これにはLCDがありません。LCDは必須なので、LCDの付いたATOMS3Rとマイクとスピーカーが付いたATOMIC ECHO BASEを使用しました。ちなみに単品で買うよりATOMS3R AI Chatbotキットを買った方がちょっと安いです。
ATOMIC BATTERY BASEはおまけで、USBポートから電源を供給しなくても、バッテリーで給電できるユニットです。バッテリーの容量は200mAなのであまり長時間は使用できませんが、デモをするときなどにワイヤレスにできて便利です。このユニットは残念ながらATOMIC BATTERY BASEに直接取り付けることができないのですが、5本のピンをカットすることで無理やり接続することができます。
さくらのAI Engineとは?
さくらのAI Engineはさくらインターネットが提供するAIサービスで、APIという形で利用できるサービスです。このようなサービスは海外には多く存在しますが、データを学習に利用せず、日本国内のサーバーのみで処理することを謳っており、どちらかというと日本の企業向けのサービスって感じです。
私も正直さくらのAI Engineにはあまり興味を持ってなかったのですが、VOICEVOX音声モデル対応というニュースを見て、なんかさくらがおもしれーこと始めたぞ!っと興味がわきました。
音声合成 TTS

VOICEVOXはローカルのPCで簡単にサーバーが構築できますし、APIのみを提供する無料のサービスもあります。しかし個人が好意で提供しているサービスは基本的に無保証ですし、大量に使ったらBANされるでしょう。さくらのAI Engineなら使用料を払えばいくらでも使えます。自前でホスティング&メンテナンスするのにかかる手間/費用と、APIの費用を天秤にかけて使い分けていくのがいいと思います。
音声合成の料金はこのブログを書いてる時点で 3円 / 10,000モーラ。モーラって何だ?? 『モーラとは、かな1字分の音の長さを表す単位』だそうです。ということは「こんにちは、ボクはずんだもんなのだ」と喋ったら17文字なので 3 * (17 / 10000) = 0.0051円。PC立ち上げっぱなしの電気代よりAPIの方が安いじゃん。もう音声合成これでいいですね。ちなみに月50回まで無料枠があります。
音声認識 STT
現在さくらのAI Engineでは音声認識のモデルとして whisper-large-v3-turbo が提供されています。MP3やWAV形式の音声データを入力すると文字起こしされたテキストが返ってくるものです。音声ファイルは30分 or 30MBまで対応しているようです。ちなみにこのwhisperってモデル、無音データを渡すと「ご視聴ありがとうございました」とか文字起こしされますww 何で学習したのかバレバレ
チャット LLM
チャット用のLLMモデルでは現在以下のようなモデルが使用できるようです。(無料プランの場合)
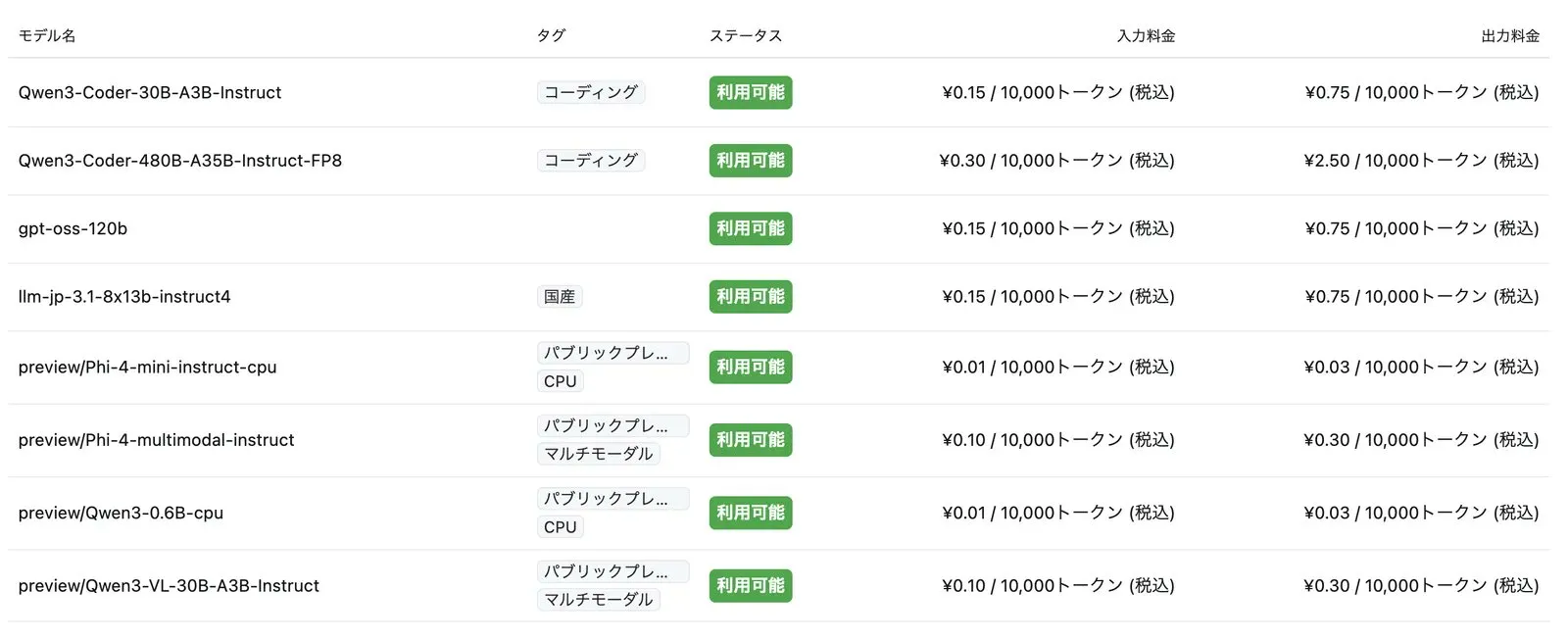
Qwen3-CoderはAlibabaが開発したプログラミング向けのモデル、gpt-oss-120bはOpenAI系のGPT技術をベースに、オープンソースコミュニティが公開した大規模AIモデル、llm-jp-3.1はLLM-jp(日本の大学・企業による共同研究プロジェクト)が開発した、日本語の理解や文章生成を得意とするAIモデル、Phi-4はMicrosoft開発した小型で高効率な推論を目的に設計されたモデルです。(※ChatGPT調べ)
え?これだけですか?今だと大幅に性能が上がったQwen3.5とか、他のサービスなら色々あるのに少ないですね。企業用途を想定したいろんな大人の事情を考慮した結果なんでしょうかね。
VOICEVOXの使い方
さくらのAI Engineのドキュメントは こちら にあります(APIのドキュメントは こちら)。初めての人は会員IDの取得、プロジェクトの作成、アカウントトークンの取得と最初にやることが多くてちょっと大変です。まずはアカウントトークンの取得まで頑張りましょう。
簡単な音声合成の手順
まずはドキュメントに書いてある内容通りの音声合成を試してみます。以下はWSLでの実行例です。
# アクセストークの設定
export TOKEN='ここにアクセストークンを入れる'
# 音声合成
curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/audio/speech \
--header "accept: audio/wav" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"model": "zundamon",
"input": "こんにちは、ボクはずんだもんなのだ。",
"voice": "normal",
"response_format": "wav"
}' \
--output audio.wav
# 再生
powershell.exe -c "(New-Object Media.SoundPlayer 'audio.wav').PlaySync();"成功すれば「こんにちは、ボクはずんだもんなのだ。」と喋るはずです。
このAPIはさくら独自のもの(OpenAI互換かもしれない)で、従来のVOICEVOX独自のAPIを使う場合は以下のようにします。
# アクセストークの設定
export TOKEN='ここにアクセストークンを入れる'
# 音声合成用のクエリを取得
curl --request POST \
--url "https://api.ai.sakura.ad.jp/tts/v1/audio_query" \
--header "Authorization: Bearer ${TOKEN}" \
--header "accept: application/json" \
--get \
--data-urlencode "text=こんにちは、ボクはずんだもんなのだ。" \
--data-urlencode "speaker=3" \
--output audio_query.json
# 音声合成
curl --request POST \
--url "https://api.ai.sakura.ad.jp/tts/v1/synthesis?speaker=3" \
--header "Authorization: Bearer ${TOKEN}" \
--header "accept: audio/wav" \
--header "Content-Type: application/json" \
--data-binary "@audio_query.json" \
--output audio.wav
# 再生
powershell.exe -c "(New-Object Media.SoundPlayer 'audio.wav').PlaySync();"これなら https://api.ai.sakura.ad.jp/tts/v1/ のところを http://192.168.xx.xx:50021/ に入れ替えるだけで、ローカルのVOICEVOXサーバーや他のAPIに切り替えられるはずです。今回作成したプログラムでもこのようなVOICEVOX独自APIを使っています。
プログラム
今回作成したプログラムは GitHub にアップしました。
必要な設定
変更が必要な箇所は以下の3行です。Wi-FiのSSIDとパスワードと、さくらのAI Engineのアクセストークンを書き換えます。
// 基本設定(各自の環境に合わせて変更してください)
#define WIFI_SSID "****"
#define WIFI_PASSWORD "****"
const String SAKURA_APIKEY = "****"; // 有料「有料」って書いてあるのは気にしないでください。消し忘れです。月50回までなら無料で使えるはずです。
動作の流れ
1. ボタンを押すと録音開始
2. 無音検知(またはボタン押し)で録音終了し、WAVデータを生成
3. WAVデータを音声認識 STT APIに送信して文字起こし
4. CHAT APIで「ずんだもん口調」に変換
5. 音声合成 TTS API (VOICEVOX)に送信し、WAVデータを受信
6. WAVデータを再生、リップシンク更新
リップシンクは今まではVOICEVOXの /audio_query で取得したJSONデータを元に a, i, u, e, o, n の更新をしていましたが、今回は音声の強弱レベルで a, o, n のみ更新する方式にしました。
なお、アバターCLASS以外はほぼAIで作ってます。GPT-5.3 Codexはマイコン系のプログラムも失敗なく作れることが多いですね。Composer 1.5は速いけどドツボにはまると抜けられなくなります。最新のWeb情報を勝手に取りに行ってくれるので、学習されてない新しい情報も取り込んで反映してくれるのが便利です。
画像のカスタマイズ
ずんだもんの表示は坂本アヒルさんの立ち絵素材を使用させていただきました。アバターの表示はズンダチャンやzundabreak2、zundabreak2_atombaseで使ったアバターCLASS (Zundavater)をそのまま使ってます。画像のカスタマイズやオリジナル画像を使いたい方は こちら を参考にしてみてください。
ずんだもんの画像はそのままでポーズだけを変えたいという場合は、プログラム中の以下の部分の数字を変えるだけでOKです。
// 聞く(録音)
avatar.changeParts("body", 0); // 体
avatar.changeParts("rhand", 6); // 右腕 マイク
avatar.changeParts("lhand", 0); // 左腕
avatar.changeParts("eyebrow", 0); // 眉毛
avatar.changeParts("eye", 1); // 目
avatar.changeParts("mouth", 0); // 口
avatar.changeParts("ahiru", 0); // アヒル
avatar.drawAvatar(); // アバター全体表示data_image_zundamon128.h の先頭の方には以下のようなコメントが入ってます。
uint16_t imgTableEyebrow[] = { 16, 17, 18, 19, 20 };
// [0] = 眉 ニコニコ (普通)
// [1] = 眉 \ / (怒り眉)
// [2] = 眉 / \ (下がり眉)
// [3] = 眉 困り眉1
// [4] = 眉 困り眉2たとえば眉毛”eyebrow”のところは avatar.changeParts(“eyebrow”, 0); となっていますが、この 0 という数字が「[0] = 眉 ニコニコ (普通)」を意味しています。実際のイメージは坂本アヒルさんのPSDファイルを開いて、それぞれのレイヤーをON/OFFして確認してみてください。
さくらのAI Engineを使ってみた感想
今回はじめてさくらのAI Engineを使ってみましたが、VOICEVOXが安価で使えるというのはとても素晴らしいです。VOICEVOXという日本の音声合成エンジンを、サービスとして提供できたのも日本の会社だからこそ進めやすかったでしょう。VOICEVOX独自のAPIも残してくれたのも良いですね。今回は無加工で行いましたが、音声のピッチを変えたり、詳細なリップシンクを再現することも可能になっています。
一方で使用できるモデルが非常に少なく、選択肢が限られているのが残念なところです。国内・日本企業という縛りがないのであれば、さくらでなくてもいいでしょう。私のような趣味の工作で使う用途ではあまりそのへんは重要ではないので、OpenRouterみたいなサービスを使っていろんなモデルを試してみる、という方が楽しいと思います。
とはいえVOICEVOXが使えるというのはとても便利なので、VOICEVOXだけさくらを使うというのはありだと思います。今回作成したプログラムでは以下のようにSTT, CHAT, TTSそれぞれのAPIのエンドポイントとキーを設定できるようになっているので、部分的に入れ替えて使うこともできるはずです。試してませんが。
const String TTS_ENDPOINT = "https://api.ai.sakura.ad.jp/tts/v1";
const String TTS_APIKEY = SAKURA_APIKEY;
const int VOICEVOX_SPEAKER = 3; // 音声合成モデル(ずんだもん あまあま)
const String STT_ENDPOINT = "https://api.ai.sakura.ad.jp/v1";
const String STT_MODEL = "whisper-large-v3-turbo"; // 音声認識用モデル
const String STT_APIKEY = SAKURA_APIKEY;
const String CHAT_ENDPOINT = "https://api.ai.sakura.ad.jp/v1";
const String CHAT_MODEL = "gpt-oss-120b"; // CHAT用モデル
// const String CHAT_MODEL = "Qwen3-Coder-30B-A3B-Instruct"; // コーディング用モデル
// const String CHAT_MODEL = "llm-jp-3.1-8x13b-instruct4"; // このモデルは指示に従わないから不向き
const String CHAT_APIKEY = SAKURA_APIKEY;
const int CHAT_TTS_MAX_CHARS = 300; // TTSへ渡す文字数の上限APIのドキュメントを見ると今後実装されそうな機能もあり、今後も新しいモデルが追加されていくと思います。今後のバージョンアップにも注目していきたいと思います。