 【サイトURL】
【サイトURL】
Which is Hot?
http://WhichisHot.in/
【ブログ記事】
このカテゴリ記事一覧
前回に続きまして、今回はWhich is Hot?のシステムの概要を説明していきたいと思います。
このサイトでは2種類のデータストアを使い分けています。1つはMemcached、もう1つはTokyo Cabinet(Tokyo Tyrant)です。
Memcachedはオン・メモリのKey-Value型データストアで、メモリ内で処理するので非常に高速です。ただし電源を切ればデータは消えてしまいます。
Tokyo Cabinetはオン・ディスクのKey-Value型データストアで、Memcached並の高速な処理性能を持ちつつデータをディスクに保存するため、電源を切ってもデータは残っています。
これらの特性を生かし、高速なアクセスが必要で再構築が可能なキャッシュ用のデータはMemcachedに、永続的な保存が必要なデータはTokyo Cabinetを使用しています。小規模なサイトならRDMBSでやってもじゅうぶんでしょうけど、Key-Value型データストアは構造が単純で扱いやすいというメリットもあります。
そしてもう1つ、Tokyo CabinetのインターフェースであるTokyo TyrantはMemcachedと互換性があるのが特徴です。Memcachedのホスト名/ポート番号をTokyo Tyrantのホスト名/ポート番号に変更すれば、そのままのアクセスできてしまうので開発も容易です。
【Which is Hot?のシステム概要】(クリックで拡大)
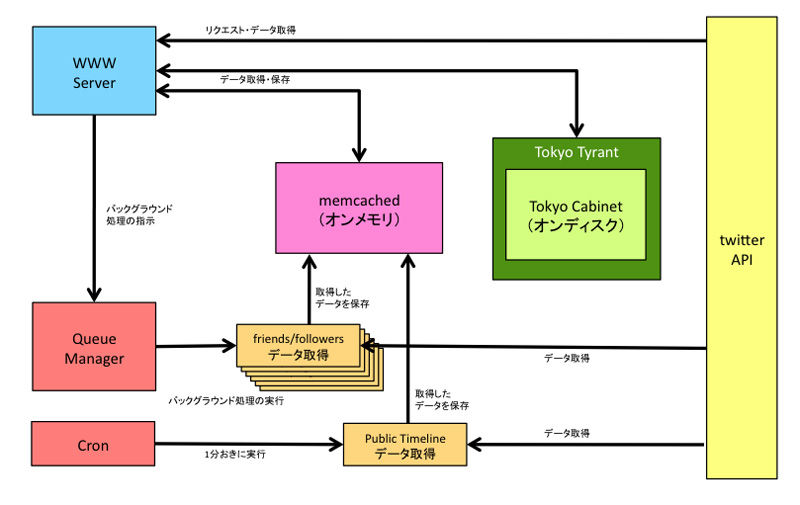
Twitter内のデータにアクセスするにはTwitter APIにアクセスして、データを取得しなければなりません。Which is Hot?ではfriendsとfollowersのIDの一覧と、個々のユーザーの情報(スクリーンネーム、アイコンのURL等)を利用します。人によっては何十万人もフォローしていたりフォロワーがいたりすることも珍しくありませんが、Twitter APIで一度に取得できる件数は限られています。そこでデータの取得はWWWサーバー側では行わず、バックグラウンドで取得することにしました。
<Twitter APIの仕様>
・friends/followersのID一覧の取得 5000件毎
・指定IDのステータス 最大100件/1リクエスト
WWWサーバーとTwitter APIの通信はOAuthによるログイン処理のみを行い、ログインに成功するとキュー・マネージャーにバックグランド処理を指示します。
friends/followers取得プログラムはすでにデータが取得済みでないか(キャッシュ有効期限内か)調べ、Twitter APIにまずID一覧取得のリクエストを送信します。10000件に達したらそれ以上は読み込みません。次にユーザー情報が取得済みでないか(キャッシュ有効期限内か)調べ、ユーザーの情報を100件取得します。
以上の処理を1セットとし、何回か繰り返します。
もしfriends/followersがそれぞれ1万人いる人の場合、ID取得が4回、ユーザー情報の取得が200回必要となります。1リクエストに3秒かかるとすると10分以上かかることになりますから、このようなバックグラウンドでの処理が必要だったのです。
さて、さきほど「何回か繰り返します」と曖昧な事を書きました。これは全部のデータを一気に読み込まず、必要に応じて読み込むようにしているからです。やってみたけど1回アクセスしただけで去ってしまう人もいるかもしれません。おそらくほとんどの人がそうかも!?(^^;) それなのにずっとデータを読み込み続けてるのは無駄ですし、1時間350リクエストまでというTwitter APIのリミット値を消費してしまいます。
そこで、少し読み込んだら一時中断します。一時中断している間に再びアクセスがあれば、再度データを取得しにいきます。つまり繰り返し遊んでくれる人のデータは、遊んでいる間にどんどんとデータを読み込んで構築されていき、途中で投げ出した人はそれ以上読み込まないという仕組みです。
ということで、今日はここまで。
次回はデータストアの詳しい使い分けについて書いていきたいと思います。
Which is Hot?http://WhichisHot.in/